
Here’s a detailed overview of functions and features that I would like to find in a Digital Asset Management System (DAM).
This is a follow-up post to the previous one I did on DAMs that has attracted quite a lot of attention and comments. As I explained there, following the death, demise and discontinuation of Extensis Portfolio I need to find a new DAM.
[update 2014-08-11] I also want to underline that I am very grateful to all those people who have commented on my previous post (more than 100 comments!). It has brought the whole discussion forward and shows that this is after all important for many people!
[update 2014-08-12] Please answer my new poll on what DAM system you use!
This is also intended as a list to help me evaluate the alternatives. Perhaps it can also be a help to others. The list of requirements may evolve as I continue the exploration, so if you’re interested in the details, do come back here or subscribe to the post. (There’s a subscription option next to the comment box below.) And perhaps it can give some useful advice to current or future DAM developers.
As it looks now, these are the programs that I could be looking at. For each I plan to write a test report:
- Photo Supreme (ex-iDimager)
- Daminion
- Media Pro, by Phase One
- digiKam, open source
And then these, that I have previously seen as browsers but that others have pointed to as potential DAM solutions:
- ACDsee (“plain” or Pro? I don’t know yet)
- IMatch
Possibly these, but they seem too expensive to be a serious alternative for an independent photographer:
- DBGallery
- FotoStation, FotoWare
Have I missed some potential DAM?
I should also add that I do not expect to be looking at:
- Lightroom, Adobe
I have not looked at it in detail but many photographers emphasise that it is good for some tasks but it is not at all a proper, fully-fledged DAM. Apparently it lacks important features to be considered a DAM. Perhaps it is one of the Swiss Army Knives I mention below.
I plan to publish reviews / tests / comparisons of the DAMs as I do them.
I would like to underline, once again, that I do not want the DAM system to do image editing for me. I do not use a DAM for adjusting colour, contrast, cropping, converting etc, etc. I use other dedicated and more competent programs for that: Phase One’s Capture One, Adobe Photoshop and others. Don’t confuse a DAM with a photo Swiss Army Knife.
I use my DAM to catalogue, organise, assign metadata, and find images. That’s all.
There are two reasons why I go to these lengths in finding a new DAM:
- The DAM is a vitally critical tool to manage the images and data regarding the images. Without a good DAM it is impossible to use the images to their full value.
- Keywording and adding Descriptions / Captions to images is an immensely time-consuming (and boring) task, so to have tools that make it easier and faster is a great help.
I should also underline that my perspective is that of an independent photographers, working mainly with stock photography, working with multiple photo agencies.
Other photographers in other situations will have different requirements. (Please share them with me in the comments section!)
NB: The numbering below with some A, B, C after the heading number etc is of no significance. It is just because I have added items after the intital number and I don’t want to change the numbering.
1. General company considerations
There are various aspects of the company who makes the sw that can have an impact on your decision.
2. Price
Of course.
3. Installation
Not much to say. It should be easy and go smoothly.
Note 1: I am only interested in DAMs that are installed locally. I am not interested in cloud based DAMs.
Note 2: I work on Windows, currently using Windows 7, 64 bit. Many photographers like the Apple world but I do not use it.
[Update 2014-08-10] It should be possible to choose where the data file(s) – the catalogue – is stored. I have all personal program data files, like for example my catalogue files, stored in a “personal data files” folder. This greatly simplifies back-up. It becomes very difficult to implement an effective back-up strategy if programs do not allow me to decide where data should be stored.
3 B. Performance [update 2014-08-10]
How long time does it take to catalogue images?
General performance considerations.
3 C. User interface [update 2014-08-10]
General user interface considerations.
4. File server compatible
The DAM must be able to work with files located on a file server connected over a network.
5. Off-line capable
The DAM must be able to function even if the files in the catalogue are not available, for example when travelling or if the file server where they are located is off-line.
6. A cataloguer, not a browser
It must be a cataloguer, not a browser. In other words, the catalogue data should be stored in a catalogue file, separate from the files themselves. Nor is it acceptable that the catalogue data is stored “distributed” in various places, as for example Adobe Bridge does with its .BridgeCache and .BridgeCacheT files.
This is also very important for your back-up strategy. You have to be able to back-up the catalogue data.
7. Basic Metadata, Keywords and Description / Caption
This is so basic so that it is hardly worth mentioning, but just for the sake of completion:
Apply keywords and caption (aka “description”) – this is the key to the whole application!
Keywords and descriptions can be added to multiple files at the same time.
A note on hierarchical keywords: I do not need the DAM to handle hierarchical keywords. Hierarchical keywords, or a “controlled vocabulary”, can be a good tool in some situations to find good keywords. But hierarchical keywords / a controlled vocabulary is too rigid a structure for it to be applicable when keywording images in a DAM.
7 B. Appending text to Description / Caption in multiple images [update 2014-08-10]
It should be possible to append text to Description (Caption) field for multiple images at the same time.
Example:
One image has the Description/Caption “church”, another “theatre”. It should be possible to append to the end of the caption “, bilbao” for both images in one go.
This is very important.
7 C. Dragging and dropping keywords [update 2014-08-10]
This is perhaps not a vital feature but it is very useful:
The possibility to drag and drop a text from e.g. Word onto a selection of thumbnails and they are then applied as keywords to those images.
Example: I have in a Word document the text string “theatre, theater, opera house”. Dragging and dropping it over a selection of thumbnails applies those three keywords as separate keywords (opera house being applied as one since it is not comma delimited).
It is of course possible to copy and paste into the keywords field but a drag and drop can be very simple and faster.
8. Embedding of metadata in the files
This is also very basic: embedding the metadata that has been done either in the files themselves (when possible) or as sidecar files.
My preference is to embed it in the files themselves. This is a much stronger security than when embedding it in separate “sidecar” files. But the best would be if the sw gives you the option for either. For some file types (proprietary raw files) embedding is not an option though.
One additional consideration:
Is the embedding instantaneous in the files or is it done with a separate command?
Instantaneous: as soon as you change a metadata, e.g. a keyword, it is written to the file. This is not a good option in my view. Yes it assures that it is instantly saved to the files but it has several drawbacks. First, if you work with batches of files and add keywords to many files at the same time it will mean a very large number of file opens and saves. For example: I may want to add the keyword Bordeaux to 1000 files simultaneously. This will lead to 1000 file opens and saves. I then add France to the same files. Again 1000 file opens and saves. Each open and save takes time and risks corrupting the file. Also, if I have generational backups it will generate a huge number of generations over time.
With a separate command: This means I add metadata in the cataloguer to any number of images I want. The keywords/description is only stored in the DAM and not embedded into the file. I then use an “embed” command to make the DAM write all the metadata from the DAM to the files that I have selected. This is much better.
9. Import and export of catalogue data fields to txt / csv / xls
It must be possible to export all data fields, such as keywords, etc, including custom fields to text files, xls files etc.
It must also be possible to import the same.
This is the only way to avoid being locked-in to a solution.
It is also important for many other reasons. For example:
- “Standard” metadata fields are not sufficient (see custom fields) and I am not comfortable with designing my own XMP things. Therefore some metadata will reside only in the DAM and I will need to be able to extract / export that.
- I need to be able to supply this information to the agency(ies) I work with. For instance, although in principle Alamy reads metadata from the files this does not always work on their systems. Also: they require (or at least strongly recommends) other information that simply does not exist in embedded metadata. On the other hand, these exist as custom fields in my current DAM. For example, they have these Alamy specific fields: Caption (a short version of Description), Essential Keywords, Main Keywords. These can easily be created by manipulating the data in a spreadsheet.
- Also: For some file types, embedding metadata is not an option. You should not embed in proprietary raw file formats. For such files it is important to be able to export all metadata that has been entered in the DAM.
This is a very important feature to avoid being locked-in to any DAM.
10. Custom Fields
The user must have the possibility to define custom fields.
It is preferable if the custom fields have some “advanced configuration” possibilities. For example:
- Define that the custom field is of certain types
- Numeric
- Decimal
- Date / time
- Text string (of a pre-defined length; or not)
- URL
- ….
- Define that the custom field can have a single value or multiple values (examples: “keyword” is a field that can have multiple values, “date created” is a field that can have only a single value)
- Define that the value of a custom filed must be a pre-defined list. (There could also be a pre-defined list, but other values are allowed too although I have never had any use for this.)
Extensis Portfolio does this very, very well.
In most cases Custom Fields is data that is not embedded in the files. The Custom Field data exists only in the DAM. Primarily because they are, well, custom, specific for the user, and not part of a standard metadata definition.
Custom fields are very important.
Custom Fields are important.
For example, I use custom fields for this:
- For the non-standard three levels of description that for example Alamy (a stock agency) requires. (Text fields of pre-defined length.)
- To keep track of where in my workflow an image is and where in my keywording process it is. (Text fields that can only have certain pre-defined mutually exclusive values, e.g.: [does not exist], Processing, Finished, Do Not Process)
- What the status is of an image with an agency: not submitted, submitted, accepted, rejected… (Same type of pre-defined list with mutually exclusive values.)
- For raw files: what shoot the image is from. I do not embed metadata in raw files. (Same type of pre-defined list with mutually exclusive values: Paris, Bordeaux, South Africa,…)
- etc
11. Perform “advanced” searches on Custom Fields
The DAM must be able to search / find custom fields, but not only that. It has to be able to do advanced searches combining multiple fields and using logical operators.
Example:
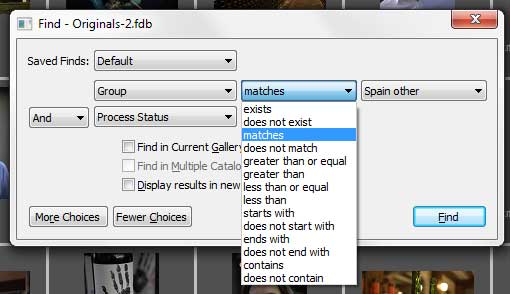
This example is from my RAW file catalogue and illustrates one part of my workflow.
I have a custom field called Group. It actually denotes the region the shot has been taken in. (Remember, much of my photography is travel.) The Group custom field can have values such as Burgundy, Spain, South Africa etc.
I have another custom field called Processing Status. Processing Status indicates where in my processing workflow the file/photo is. It can have the values [blank] (i.e. no value at all), Processing, and Finished Processing. [blank] means I have not started work on this file. Processing means I have “checked it out” and am processing it (doing the raw processing and keywording). Finished Processing is when all the work has been done and there is a processed and keyworded version of this file in the Develops catalogue. Or as the case may be, no finished file at all if I thought the photo was not worth processing.
I use this to do this kind of searches:
- Find all files from Spain that I have not started working on yet. (Group = Spain AND Processing Status = [blank])
- Find all files that are from either Spain or Italy. (Group = Spain OR Group = Italy)
The advanced search function should preferably have at least these functions:
This is how it looks in Extensis Portfolio. Very good!
It also shows this:
You must have the possibility to combine several custom fields (or the same multiple times) with an AND / OR operator.
The example also shows the option to only search in the currently displayed set of images, or in the whole catalogue, or even in multiple catalogues.
It is also handy to be able to save (and name) searches that you do often.
12. Virtual Galleries / Temporary Sets / Categories – hierarchical
The possibility to organise images in virtual galleries or temporary sets. In Extensis Portfolio this is called “categories”.
This is very similar to a folder structure on a disk but it is simply a virtual organisation. It is not anything that has to do with how the images are physically organised on the disc.
It must be possible to organise the Virtual Galleries in a hierarchy, with images on all levels in the hierarchy.
This is similar to a “controlled vocabulary” but is in fact totally separate. It has actually nothing to do with a vocabulary or keywords, although it looks similar.
It should be possible to have the Virtual Gallery hierarchy open in one part of the window and the thumbnails in another part of the window and then place images in the Virtual Gallery structure by dragging and dropping the thumbnails.
This is a huge time saver for me when assigning keywords and description.
Example:
I could have a Virtual Gallery structure that looks like this (but much, much more elaborate):
– Architecture
-.- Buildings
-.-.- Religious
-.-.-.- Church
-.-.-.- Monastery
-.-.- Business
-.-.-.- Office
Etc, etc. Before assigning keywords and descriptions to a large number of images I would drag-and-drop the images into these Virtual Galleries so that I then can assign similar and relevant keywords and descriptions to similar images.
13. Folder Watching
A file in the catalogue may be, accidentally or intentionally have been modified by another program. The DAM needs to be able to identify and flag discrepancies between the catalogued file and the file on disk.
Another case, new files, or folders, may be added outside the catalogue to the archive folders (the folders where the catalogued files reside). The DAM should be able to identify and flag this too.
Preferably this should be possible to do in an automated way, meaning that you should be able to turn it on and the DAM will check and alert you automatically or off and the DAM will only check when you ask it.
14. Changing file paths
It must be possible to change the location (paths) of files in batches.
Explanation:
Folder and drive structures change. If image files are moved from one location to another, for example a folder is moved to a different drive or to a different folder tree, it must be possible to change the location of all moved files in a batch, not only one-by-one.
15. Multiple catalogues
I think that it is a good idea to work with multiple catalogues. You can do this in different ways, for example one catalogue per year. This can be for organisational reasons or performance reasons.
Personally I have separate catalogues for my RAW files and for my Develops files.
In addition, due to file size constraints and performance reason I have split my RAW catalogue into three separate catalogues. (I have 140,000 raw files.)
16. Use and Search multiple catalogues
This is perhaps more of a “nice to have”, depending on your needs.
The possibility to have multiple catalogues open simultaneously and to do a search/find across multiple catalogues with a single command.
Many people choose to split up their collection in multiple catalogues, e.g. by year or some other logic. Therefor it can be convenient to be able to search multiple catalogues in one go.
17. Special administrative searches / finds [update 2014-08-10]
Some “special” finds or seraches should be possible. For example, searches for:
- Duplicate files (same file name)
- Missing files / missing “originals” (files that exist in the catalogue but cannot be found on the disk)
- And if relevant:
- unreadable items
- partially catalogued items
- perhaps others too
If you have any question on what any of the above means, do not hesitate to post a comment and ask!
I had a comment on a forum that I think is so interesting that I would like to share it here:
—
I have one quibble. For item #7 (keywords/captions) you say:
“A note on hierarchical keywords: I do not need the DAM to handle hierarchical keywords. Hierarchical keywords, or a “controlled vocabulary”, can be a good tool in some situations to find good keywords. But hierarchical keywords / a controlled vocabulary is too rigid a structure for it to be applicable when keywording images in a DAM.”
I’m not sure what you mean by this statement. A controlled vocabulary is not the same as hierarchical keywords. As I understand it, a controlled vocabulary is a managed list (or lists) of regular keywords, whereas (a set of) hierarchical keywords is a specific type of controlled vocabulary that lets you define relationships between keywords.
These tools are implemented separately in Expression Media/Media Pro and both are essential to my use of the software (I actually still use Expression Media).
I have found hierarchical keywords to be especially useful because of their memorized structure. If you’re cataloguing wildlife (named according to a strict scientific/taxonomic structure that can consist of a dozen keywords), hierarchical keywords can save hours of time when applied to future images.
These are precisely the features I expect from a DAM.
—
Here’s my answer:
Yes, I agree, hierarchical keywords (HK) and a controlled vocabulary (CV) is not the same thing.
And yes, I can understand that many people would find either or both a HK and CV very useful. I can also understand that for some it would be a critical component of a DAM.
However, not for me, not for the way I work.
I tried for some time to use David Rieck’s Controlled Vocabulary (http://www.controlledvocabulary.com/) and have also occasionally tried using HK. But I always found it to be too rigid.
On the other hand I have used it as “inspiration”, but in a more flexible way, to help feed my own keyword lists.
I think that i CV would be most relevant in a “closed” environment, within an organisation. But when you are working with “publicly” available stock the “controlled” part is too limiting. Instead you have to be imaginative. You have instead to try and think of “what possible search terms could people use and be happy to find this picture?”
And HK is obviously useful when you work with e.g. botanical subjects with a clear hierarchy. But I generally don’t
But then again, if I found a good DAM that had a CV or HK perhaps I would find a good way to use them. (BTW that is actually a feature that my current DAM, Portfolio, does NOT have.)
It’s my understanding that Controlled Vocabularies refer to *content* while Hierachies refer to *structure*.
I am currently cleaning up a 3600+ word flat, messy, disorganized keyword list for my new employer. We have healthcare-specific keywords that would not likely appear in a generic CV dataset like that by David Rieck. In effect, I’m building my own CV based on the vocab we actually need. That only addresses the content, however.
The structure is also important. I leverage Hierarchical Keywords to organize the vocab I am building into logical genus-specis type order, and also to apply multiple relevant parent keywords. For example, knowing where a photo was made is useful, so I have rooms and departments inside buildings inside facilities inside cities. I can apply Cityville > ABC Campus > North Building > XYZ Department simply by applying the most child keyword.
In that way, I find that CV and MK are not the same, CV and MK are not mutually exclusive, and in fact CV and MK work hand-in-hand to make keywording more efficient and more robust.
Here’s another very interesting comment that I take the liberty to copy from a thread on the excellent Media Pro user-to-user forum (http://goo.gl/bfL0ss)
—
Interesting indeed. I follow all the dam tools and it will be very interesting how you compare them.
I also have a few notes. Right now I can’t reply in detail but some short ones: you have the company as your first criterium. I think this is meaningless. We’ve seen enough of the big companies dropping their tools without notice. This includes Adobe, Microsoft, Apple (recently), extensis (recently), canto (recently), Corel (recently), and more. Maybe a valid aspect in this area is how long a product is in the market. Anything else is “air”.
Also, your criteria are based on existing features here. For example; how you describe the portfolio “categories” is not what I would call virtual galleries, though you could use it for that purpose.
Your ideas about embedding metadata are outdated and more based on the limitations of Portfolio.
Export to CSV etc; your argument is that export and import is a requirement to be “the only way to guarantee independence” is also outdated. How you describe it for Portfolio this does make sense for you to get your data in your new DAM, but once working with other dams you shouldn’t need its import. There are more, and more efficient, ways to achieve the same.
Your search requirement is based on portfolio. While I agree with the requirement, I disagree with that outdated dialog to achieve this.
Multiple catalogues and searching over them are a result of the limitations of Portfolio. Is that still 2Gb? Any modern dam can store up to terabytes in a single database. Searching over multiple databases, at least to me, seems like you shouldn’t have separated them in the first place. But I do understand that if a dam only supports 2GB databases that this is a requirement.
It’s not my intention to criticize your approach, but I want to illustrate that some requirements are not always relevant or my be open for different interpretations. Good luck with your comparisons. And don’t forget; the devil is always in the details with these tools and getting to the details takes lots of time. And they change with every update of the software.
—
You are absolutely right, my comments are based on my habit of working with Portfolio. Inevitably. In time, after changing, the way I work may very well change.
I don’t agree with your comment on “company”. It is a matter of taking an informed decision. But I still think it is important to know a bit about who’s behind it. Is it a big company, famous for its poor customer support and bullying? Is it a small one-man shop? It is impossible to predict the future but it is better to know something about the current situation.
Also, I am not saying that I want a new DAM to do exactly what Portfolio does, I am just trying to find ways of performing the tasks that I need to do in a DAM. Inevitably I use terminology from Portfolio since that is my current tool. For example the “virtual galleries” is a tool that significantly speeds up my keywording. (If Portfolio’s “categories” were intended in another way is beside the point. What is important is what it allows me to do.)
I don’t see why “Export to CSV etc; your argument is that export and import is a requirement to be “the only way to guarantee independence” is also outdated.”. Unless you rely 100% on embedded metadata, or on sidecar files I don’t see how it can be outdated.
Also, it is an important tool for me to provide data to Alamy. I don’t see how I could do that in any other way. I’d be happy to learn!
Your other points on limitations in Portfolio and that it is outdated (it certainly is!) may or may not also be relevant for other DAM. Remains to be seen.
I definitely agree with your conclusion, the devil is in the details. It is not sufficient to look at specs or have a quick run-through of the SW. You have to go through all the workflow process in detail and see how it works for you!
I’d be curious to know what you suggest today as DAM!
Question #1: I would be interested to hear whether you or anyone else has considered Filemaker Pro 13. It is a generic database software that can be customized for a variety of purposes. I am trying to transfer files from Portfolio 8.5 to another database system and it is proving to be quite painful. So far I have been able to export the Portfolio data and import it into Filemaker, but the images don’t transfer, so that is really not very helpful! I am quite distressed that Extensis pulled the plug. It seems like *some* company out there should want to scoop up those customers who just want an easy-to-use stand-alone (not cloud-based!) DAM…
Question #2: With the various DAM solutions you are exploring, I am wondering about the ease of transfer from Portfolio. Any thoughts/experience regarding this?
Thanks in advance for your helpful post!!!
I too am in the position of trying to find another horse in the middle of the stream.
Yesterday I published this on Medium.
Photo Management
Apple announced that Aperture was not going to be maintained. Old news. Of course all work on it stopped, and all plugin development stopped.
Now, Aperture wasn’t the bee’s knees by any stretch of the imagination. But since then I’ve been searching for a replacement. Much like a Swiss army knife, it did many things in a convenient bundle, but didn’t do any of them really well.
So far all I’ve found, to carry on the metaphor, are sheath knifes, dremel tools, scalpels, and empty cardboard boxes. Lightroom comes closest — it’s more of a leatherman. Does lots of things, but uncomfortable in the hand.
Here’s the dilemma:
Most of the alternative products proposed are for editing images. Photoshop, Lightroom are the big boys, Affinity, Photo Supreme, Aftershot Pro are candidates.
But editing is no good if you can’t find the image to start with. My situation: I have a tree farm. I try to take at least 100 pictures a month, to be used for catalogs, mailouts, blogs, newsletters. On occasion I have picked up my camera and gone out to the field, because I couldn’t find the pic I wanted in my archives. I don’t edit much. But I need to be able to find what I took 10 or 20 years ago.
Photo Mechanic is a good tool in the chain: It’s probably best of breed for keywording, rating, captioning, and culling. It’s a decent browser, but it’s no good as a search tool.
Lightroom has moderate ability in keywording — interface is clunky, but it understands hierarchies. Haven’t really tried it yet for searching. LR has a 7 day trial, which is hardly enough to find your way.
I’ve found that there are four distinct tasks to deal with once you have more than a few thousand photos.
1. The ability to add metadata: Keywords, captions, descriptions. Computers don’t understand, “Find me that pic I took of maple trees on a sunny winter day, around Christmas time.”
2. The ability to search for images by using that metadata. Now I can find keyword: Maple trees; Date 20 to 30 December. Search is implied with Smart Albums — Albums that you don’t add images one by one, but ones that are based on metadata. E.g. “Last 4 weeks” “Spring Inventory” “Facebook Shares” The first is based on image dates, the next two on keywords.
3. The ability to edit images, both destructively, or non-destructively. A non-destructive edit eventually has to be turned into an new image to be used outside the PMD. This does not have to be handled by the PMD, but until I get a camera that does what I mean, instead of what I told it to, I will need to edit images.
4. The ability to track multiple versions of a file. Those non-destructive edits have to be converted to a new image at some point if they are going to be used. Nobody tracks the offspring at this point.
Photo Mechanic excels at task 1. It understands hierarchies — that “maple” may be a tree or a flavour of syrup, or cabinet wood or even (shudder) a formica pattern. It understands synonyms: When you label something Maple (tree) it can fill in Acer, the botanical genus name. It will also put in the parents of the hierarchy.
Aperture isn’t bad at task 2, although you start having problems if you want to do things like “Show me images that would fit in a 1024 pixel box.” as when you reduce that to exif pixel searches, you need both OR and AND in your search, which Aperture doesn’t do.
Editing: See the list above. There are others, but they are either very cheap and very limited, or they cost your firstborn son, or they are Software as a Service, and require a monthly pint of blood.
Versioning: Not there yet. Not really. Both Aperture and Lightroom implement “Stacks” where you can put in related images — You have the continuous shooting going on, so you have 15 pictures taken in 3 seconds. Lump them together. Nice first step, but a long way between a toddler’s first step, and running a marathon.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — —
In different circumstances you will want to use different tools, the Aperture habit of slurping everything into a managed library isn’t acceptable. The pictures have to be in the file system where you can find them, not hidden away.
But this exposes your database to mangling by someone moving or renaming files. Your Photo Manager Database (PMD from now on) thinks that the maple shot is in /Path/To/Pix/Masters/2016/12/25/DSC_1293.jpg. If you move it or rename it, then the database can’t find it. This is not an unsolvable problem. I’ll talk about two ways:
A: FSwatch is a program available on unix, linux, mac and windows for monitoring file system changes. It can tell you that a file was moved, renamed, opened with a particular app. There are others out there I’m sure.
Still, this might not be enough. The moves may come too fast. The watcher program may crash. The PMD may not be paying attention to the Watcher.
B: The second way is more complicated, but it also solves problem 4 above.
Almost all image files support some types of metadata. Most are writeable, although some with limitations. (E.g. some raw camera formats allow you to change data, but not to change the length. Change Dog to Cat, but not to horse. Horse makes it 2 characters longer. Fortunately there are usually blank fields that can be used. This will be one of those “devil in the details” problems that software designers are paid for.
Exiftool, ImageMagick, and Exiv2 are tools that can read and translate this stuff, so developers don’t have to reinvent this particular wheel.
Another useful idea is that of a checksum. This is at heart a complicated math function that uses all or part of a file as input, and produces a stream of alphabet soup as output. It’s repeatable: Same file chunk in, same soup out. Change 1 bit of the input, get new flavour of soup. Chances of 2 files having the same checksum are billions to one. A checksum is a fingerprint, unique to the file, typically 32 bytes to 128 bytes long
Let’s see what we can do with these tools:
Compute a checksum, such as MD5 on the image part of the data. This gets done by whatever program you use for importing the image. These are 2 images — shot 3/10 of a second apart, in jpeg and raw (nef). Entirely different checksums.
MD5 ./2016–12–25_14–52–23.20.JPG = 2d501ae28886ba3e17ef00f96cb321ac
MD5 ./2016–12–25_14–52–23.20.NEF = 75205c6c565a367b309953aea39fa1db
MD5 ./2016–12–25_14–52–23.50.JPG = b1c41a9a9f93cf612415ff7beffb0496
MD5 ./2016–12–25_14–52–23.50.NEF = d50d822d1efdecd4f3c1c9da32f522f1
Now we are going to make a habit of keeping a few metadata fields in all of our images. These will checksum just the image part of the file, not the metadata part. Otherwise the checksum would change every time you added a keyword.
Original Image Checksum (OIC) when we bring an image into our PMD — Unless it already has this field. This field may be written into one of the IPTC fields that are largely unused, by setting a keyword or by hijacking some other field. Keywords clutter up user space, and so should be avoided. The @ will put it at the end of the list, so it’s likely to be ignored.
Generation checksum (GC) This isn’t really a checksum — take the OIC and add a 2 character string to it, starting with aa. Do another one from the same master image, and it gets ab added, third one ac. If you prefer, use a 3 digit code.
We can add timestamps to all of the above if we wish. But keep it simple for for now.
Let’s watch this in action:
We start with 2016–12–25_14–52–23.20.JPG and record the key for it @OIC=d50d822d1efdecd4f3c1c9da32f522f1
We want to post a copy of this onto facebook, so we make a copy that will fit in a 1024×1024 box. This image is given a GC=d50d822d1efdecd4f3c1c9da32f522f1-aa Later we decide to make a black and white version of our original image. This will get GC=d50d822d1efdecd4f3c1c9da32f522f1-ab Suppose now we shrank this one so that I could use it as a thumbnail on a forum. Now it’s been made from a 2nd generation imge so it gets GC=d50d822d1efdecd4f3c1c9da32f522f1-abaa
Now you have a way to identify a file even if it gets renamed or moved. Your edits are keyed to this internal name. Developers need to write a “Get Image Identifier” or “Who_Are_You” function for each type of image. A “Reconnect database to images” basically scans the image folders and pulls the ID string, and compares that to it’s internal records. This will update file moves and renames that somehow got past the Watcher (Eg. You weren’t running PMD when you moved the file.)
When we created these new images we can put them either inside the managed folders, or outside. If they are outside, PMD ignores them. You may initially want them outside for your facebook upload, then later move them back into a ‘facebook’ folder that’s managed.
Watcher sees the new files, and notifies PMD of their existence. PMD reads the OIC, looks for a GC, and if found,increments it according to what it thinks is the next unused letter pair. If not found creates one. If PMD was the program that created the file, the GC is unchanged. (Hmm. May need another metadata field to track status of this. Back to the drawing board.)
PMD at some point asks you about metadata for the new file. Depending on the programmers you may have options to “copy metadata from original, or some combination of certain fields. E.g. if your mangling was to photoshop the 3rd bridesmaid out of the image, it should no longer have her name in the people keywords. You may want to add the keyword “Facebook Album”
You may also have rules for folders: If you put a file in this folder, it gets tagged FaceBook.
But anything that creates new copy of the image on disk gets a new Generational Checksum. Two images that have the same GC should be identical.
This will overall allow multiple programs to be used on a folder-tree of images without shooting yourself in the foot. Now you can use any combination of image editors, image browsers, metadata writers you wish.
It also means that if you add a keyword to an image you can set your PMD to write it to ALL images that derive from it.
Want to write sidecar files instead of mangling the original files repeatedly? Just get the ID in the original once, and now sidecar files can carry that info. If they get separated from their image, it’s easy now to reconnect them. Worst case: Calculate the checksum on any reasonably large chunk of image data in the file, stuff that in a database,then to rebuild your database, repeat the calculations. This means you don’t write at all into the file (Necessary if using read only media) But rebuilding your database now will take a lot longer.
The only requirement is that any editor has to at least preserve the existing ID metadata. Writers of the PMD software would certify which editors they know behave nicely. The test is simple: Here’s a set of files. Edit them, and return them. Good software could go belt and suspenders, and use multiple strategies so that the metadata can always be reconnected to the right file.
This form of software has another advantage: It makes proving that you are the guy who took it a lot easier. You shoot raw. You send them Tiffs. That tiff will have a different image checksum, but it will show the OIC. If they claim ownership, ask to see the original image. If the only copies of the original image are in your hands, they will have a tough time coming up with an image that looks like yours, and has the right checksum.
The GCs won’t be unique across the world. If I give you a copy of my image, then you edit it, then your PMD may assign a GC that my PMD has already used. If you want to be world wide unique, then you need to glom on another full checksum with each generation.
Now, while I’m waiting for someone to invent this, anyone know of something that comes close?
I appreciate you bringing up that point about hierarchical keywords—I’ve definitely run into that rigidity issue myself. The controlled vocabulary approach sounds great in theory, but in practice it often feels like you’re forcing your actual tagging needs into a box that wasn’t designed for them. Did you end up finding a better workaround for handling keywords in your DAM, or do you just accept that some flexibility gets lost?